
After noticing that AI assistants struggled to understand the architectural diagrams in my blog posts, I decided to convert all diagram images in this blog to Mermaid format. This post walks through building a tool that uses Anthropic Claude to automatically convert all of the diagrams across these blog posts from images to text-based Mermaid diagrams.
The Problem
When working with AI coding assistants I noticed they couldn't effectively "see" the architectural diagrams in my blog posts, especially in our llms.txt files we created in Adding llms.txt Files to Enhance AI Model Compatibility. These diagrams contained crucial context about system architecture, AWS service relationships, and data flows - information that would be valuable for AI assistants helping readers understand or implement similar systems.
While my diagrams were PNG images, and AI models can process them, text-based formats are far more accessible and parseable. This means that AI assistants were possibly missing important architectural context when helping readers with questions about my blog posts.
The Solution: Mermaid Diagrams
Mermaid is a text-based diagramming language that renders diagrams from markdown-like syntax. Instead of this:
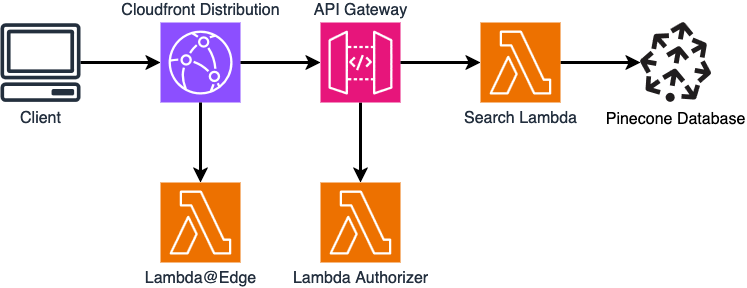
We can have this:
flowchart LR
Client((Client))
CF[CloudFront<br/>Distribution]
APIG[API Gateway]
Search[Search Lambda]
DB[(Pinecone<br/>Database)]
Edge["Lambda@Edge"]
Auth[Lambda<br/>Authorizer]
Client --> CF
CF --> APIG
CF --> Edge
APIG --> Auth
APIG --> Search
Search --> DB
style CF fill:#8C4FFF,color:#fff
style APIG fill:#8C4FFF,color:#fff
style Search fill:#FF9900,color:#fff
style Edge fill:#FF9900,color:#fff
style Auth fill:#FF9900,color:#fff
style DB fill:#3334B9,color:#fff
This format is:
- AI-readable: LLMs can understand the structure and relationships
- Version control friendly: Text diffs show meaningful changes
- Maintainable: No special tools needed to edit diagrams
- Accessible: Screen readers can interpret the content
Building the Conversion Tool
The conversion process involved three main challenges:
- Identifying diagrams vs screenshots: Not all images in blog posts are architectural diagrams
- Converting images to Mermaid: Translating visual information to text syntax
- Updating blog posts: Safely replacing images with Mermaid blocks
Image Classification
The first step was distinguishing architectural diagrams from screenshots. Using Claude's vision capabilities, we built a classifier that analyzes each image:
class ImageClassifier:
def __init__(self, converter):
self.converter = converter
def classify(self, image_path: Path) -> tuple[bool, float]:
"""Classify an image as diagram or screenshot using Claude's vision."""
classification_prompt = """Please analyze this image and determine if it's a technical diagram/architecture/flowchart that should be converted to Mermaid, or if it's a screenshot/UI/console output that should remain as an image.
Examples of DIAGRAMS (should be converted to Mermaid):
- Architecture diagrams showing system components
- Flowcharts showing processes or workflows
- Network diagrams
- Infrastructure diagrams
- Pipeline diagrams
- Sequence diagrams
- Any diagram showing relationships between components
Examples of SCREENSHOTS (should remain as images):
- Console output or terminal screenshots
- UI/interface screenshots
- Configuration screens
- Code editor screenshots
- Browser screenshots
- Dashboard screenshots
- Result outputs
- Example demonstrations
Respond with ONLY one of these two lines:
DIAGRAM: <confidence 0.0-1.0>
SCREENSHOT: <confidence 0.0-1.0>"""
try:
# Encode image to base64
base64_image = self.converter.encode_image(image_path)
# Send image to Claude for classification
if isinstance(self.converter, AnthropicMermaidConverter):
message = self.converter.client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=100,
temperature=0,
messages=[{
"role": "user",
"content": [
{"type": "text", "text": classification_prompt},
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": base64_image
}
}
]
}]
)
response = message.content[0].text.strip()
# Parse response
if response.startswith('DIAGRAM:'):
confidence = float(response.split(':')[1].strip())
return True, confidence
elif response.startswith('SCREENSHOT:'):
confidence = float(response.split(':')[1].strip())
return False, confidence
else:
# Fallback to heuristic classification
return self.classify_by_heuristics(image_path)
except Exception as e:
print(f"Error in AI classification: {e}")
return self.classify_by_heuristics(image_path)
def classify_by_heuristics(self, image_path: Path) -> tuple[bool, float]:
"""Fallback classification using filename patterns."""
filename = image_path.name.lower()
# Diagram indicators
diagram_keywords = ['architecture', 'overview', 'flow', 'diagram', 'pipeline', 'infrastructure']
if any(keyword in filename for keyword in diagram_keywords):
return True, 0.7
# Screenshot indicators
screenshot_keywords = ['screenshot', 'terminal', 'console', 'ui', 'interface']
if any(keyword in filename for keyword in screenshot_keywords):
return False, 0.7
# Default to uncertain
return False, 0.5
Mermaid Conversion
For images classified as diagrams with high confidence (≥0.8), we use Claude to generate Mermaid syntax. The conversion process includes careful prompt engineering and validation:
class AnthropicMermaidConverter:
def __init__(self, api_key: Optional[str] = None):
api_key = api_key or os.environ.get('ANTHROPIC_API_KEY')
if not api_key:
raise ValueError("Anthropic API key not provided")
self.client = anthropic.Anthropic(api_key=api_key)
def convert(self, image_path: Path, diagram_type: Optional[str] = None) -> ConversionResult:
"""Convert an image to Mermaid diagram syntax."""
try:
base64_image = self.encode_image(image_path)
prompt = self.generate_prompt(diagram_type)
message = self.client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=4000,
temperature=0.1, # Low temperature for consistent output
messages=[{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": base64_image
}
}
]
}]
)
mermaid_code = message.content[0].text
# Validate the output
if not self.validate_mermaid(mermaid_code):
return ConversionResult(
success=False,
error_message="Generated Mermaid code failed validation"
)
# Extract just the Mermaid code block
if '```mermaid' in mermaid_code:
match = re.search(r'```mermaid\n(.*?)```', mermaid_code, re.DOTALL)
if match:
mermaid_code = match.group(1).strip()
return ConversionResult(
success=True,
mermaid_code=mermaid_code,
tokens_used=message.usage.total_tokens if hasattr(message, 'usage') else 0
)
except Exception as e:
return ConversionResult(
success=False,
error_message=str(e)
)
def generate_prompt(self, diagram_type: Optional[str] = None) -> str:
"""Generate the conversion prompt with AWS-specific guidance."""
base_prompt = """Please convert this diagram image into Mermaid diagram syntax.
CRITICAL: If the image shows Lambda functions outside VPC trying to connect to resources inside nested subgraphs (like ALB inside Security Group inside Private Subnet inside VPC), you MUST use the flattened structure shown in Option A below, as Mermaid cannot render connections across multiple nested subgraph boundaries.
IMPORTANT: For AWS infrastructure and architecture diagrams, use Mermaid flowchart syntax with AWS color coding:
Flowchart syntax with AWS colors (RECOMMENDED):
- Use 'flowchart TB' (top-bottom) or 'flowchart LR' (left-right) based on layout
- Node shapes:
- Users/Clients: circle((User))
- Services/Resources: rectangle[Service Name]
- Databases: cylinder[(Database)]
- Storage: rectangle[S3 Bucket]
- Decision points: diamond{Decision?}
AWS Service Colors:
- Lambda/Compute: fill:#FF9900,color:#fff (AWS Orange)
- Storage (S3/EFS): fill:#569A31,color:#fff (AWS Green)
- Database/Analytics: fill:#205081,color:#fff or fill:#3334B9,color:#fff
- Networking (CloudFront/API Gateway/ALB): fill:#8C4FFF,color:#fff (Purple)
- Containers (ECS/Fargate): fill:#FF9900,color:#fff
- Message/Queue services: fill:#FF9900,color:#fff or fill:#B0084D,color:#fff
- Security services: fill:#DD344C,color:#fff (Red)
Label Guidelines:
- Keep labels concise but clear
- Use <br/> for line breaks in labels
- For complex names, use abbreviations: "API Gateway" → "API Gateway"
Connection Guidelines:
- Use descriptive edge labels: -->|HTTPS| or -->|WebSocket|
- Show data flow direction clearly
- Use dashed lines for optional connections: -.->
Return ONLY the mermaid code block, no explanation."""
return base_prompt
def validate_mermaid(self, mermaid_code: str) -> bool:
"""Basic validation of Mermaid syntax."""
if not mermaid_code.strip():
return False
# Check for basic Mermaid structure
if not any(keyword in mermaid_code for keyword in ['flowchart', 'graph', 'sequenceDiagram']):
return False
# Check for common syntax errors
if mermaid_code.count('[') != mermaid_code.count(']'):
return False
if mermaid_code.count('(') != mermaid_code.count(')'):
return False
return True
def encode_image(self, image_path: Path) -> str:
"""Encode image to base64 with optimization for API efficiency."""
with Image.open(image_path) as img:
# Convert to RGB if needed
if img.mode in ('RGBA', 'LA', 'P'):
background = Image.new('RGB', img.size, (255, 255, 255))
if img.mode == 'RGBA':
background.paste(img, mask=img.split()[-1])
else:
background.paste(img)
img = background
elif img.mode != 'RGB':
img = img.convert('RGB')
# Resize if too large (optimize for token usage)
max_size = (1536, 1536)
img.thumbnail(max_size, Image.Resampling.LANCZOS)
# Convert to base64
buffer = io.BytesIO()
img.save(buffer, format='JPEG', quality=85, optimize=True)
return base64.b64encode(buffer.getvalue()).decode('utf-8')
@dataclass
class ConversionResult:
"""Result of a Mermaid conversion attempt."""
success: bool
mermaid_code: Optional[str] = None
error_message: Optional[str] = None
tokens_used: int = 0
Batch Processing and File Scanning
The scanning process systematically examines all blog images and maintains state for efficient resumption:
def scan_blog_images() -> dict:
"""Scan all blog images and classify them as diagrams or screenshots."""
content_dir = Path('../../apps/web/src/content/blog')
images_dir = Path('../../apps/web/public/images')
# Initialize results structure
results = {
'scan_date': datetime.now().isoformat(),
'images': [],
'diagrams': [],
'total_images': 0,
'total_diagrams': 0
}
# Find all MDX files
mdx_files = list(content_dir.glob('*.mdx'))
print(f"Found {len(mdx_files)} blog posts to scan")
for mdx_file in mdx_files:
blog_slug = mdx_file.stem
blog_images_dir = images_dir / 'blog' / blog_slug
if not blog_images_dir.exists():
continue
# Find all image files
image_files = []
for ext in ['*.png', '*.jpg', '*.jpeg', '*.webp']:
image_files.extend(blog_images_dir.glob(ext))
# Skip header images (not content diagrams)
non_header_images = [
img for img in image_files
if 'header' not in img.name.lower()
]
print(f"Processing {blog_slug}: {len(non_header_images)} images")
for img_path in non_header_images:
# Classify each image
is_diagram, confidence = classifier.classify(img_path)
image_info = {
'path': str(img_path),
'filename': img_path.name,
'blog_slug': blog_slug,
'is_diagram': is_diagram,
'confidence': confidence
}
results['images'].append(image_info)
results['total_images'] += 1
# Only include high-confidence diagrams
if is_diagram and confidence >= 0.8:
results['diagrams'].append(image_info)
results['total_diagrams'] += 1
print(f" ✓ {img_path.name} - DIAGRAM ({confidence:.2f})")
else:
print(f" ✗ {img_path.name} - SCREENSHOT ({confidence:.2f})")
# Save results to cache for reuse
cache_dir = Path('cache')
cache_dir.mkdir(exist_ok=True)
with open(cache_dir / 'complete_scan_results.json', 'w') as f:
json.dump(results, f, indent=2)
return results
MDX File Updates
The most critical part is safely updating MDX files without breaking the blog structure:
def update_mdx_files(conversions: dict[str, str]) -> int:
"""Update MDX files by replacing image references with Mermaid blocks."""
updated_count = 0
# Group conversions by blog post
by_blog = {}
for image_path, mermaid_code in conversions.items():
path_parts = Path(image_path).parts
if 'blog' in path_parts:
blog_idx = path_parts.index('blog')
if blog_idx + 1 < len(path_parts):
blog_slug = path_parts[blog_idx + 1]
if blog_slug not in by_blog:
by_blog[blog_slug] = []
by_blog[blog_slug].append({
'filename': Path(image_path).name,
'mermaid_code': mermaid_code
})
# Create single backup directory for this run
backup_dir = Path(f'backups/{datetime.now().strftime("%Y%m%d_%H%M%S")}')
backup_dir.mkdir(parents=True, exist_ok=True)
for blog_slug, diagram_data in by_blog.items():
blog_path = Path(f'../../apps/web/src/content/blog/{blog_slug}.mdx')
if not blog_path.exists():
print(f"Warning: {blog_slug}.mdx not found")
continue
# Create backup
backup_path = backup_dir / f"{blog_slug}.mdx"
shutil.copy2(blog_path, backup_path)
# Read current content
with open(blog_path, 'r', encoding='utf-8') as f:
content = f.read()
modified = False
for diagram in diagram_data:
# Find image references using regex
# Pattern matches:
image_pattern = rf'!\[[^\]]*\]\([^)]*{re.escape(diagram["filename"])}[^)]*\)'
matches = list(re.finditer(image_pattern, content))
if matches:
# Replace with Mermaid block (take last match to avoid frontmatter)
for match in reversed(matches):
mermaid_block = f'\n\n```mermaid\n{diagram["mermaid_code"]}\n```\n'
content = content[:match.start()] + mermaid_block + content[match.end():]
modified = True
print(f" ✓ Replaced {diagram['filename']} with Mermaid")
break # Only replace one instance
else:
print(f" ⚠ Image reference not found: {diagram['filename']}")
if modified:
# Write updated content
with open(blog_path, 'w', encoding='utf-8') as f:
f.write(content)
updated_count += 1
print(f"✅ Updated {blog_slug}.mdx")
else:
print(f"⚠ No changes made to {blog_slug}.mdx")
print(f"\nBackups saved to: {backup_dir}")
return updated_count
The Streamlit Interface
The Streamlit app provides a complete workflow with progress tracking and error handling:
def main():
st.title("🎨 Mermaid Diagram Converter")
# Initialize session state with persistence
if 'conversions' not in st.session_state:
conversions_file = Path('cache/conversions.json')
if conversions_file.exists():
with open(conversions_file, 'r') as f:
st.session_state.conversions = json.load(f)
else:
st.session_state.conversions = {}
# Sidebar navigation
with st.sidebar:
mode = st.radio("Select Mode", [
"📊 Dashboard",
"✨ Convert Diagrams",
"📝 Apply to Blog Posts"
])
# Integrated scanning
if st.button("🚀 Scan Blog Images", type="primary"):
run_integrated_scan()
# Main content areas
if mode == "📊 Dashboard":
show_dashboard_with_progress()
elif mode == "✨ Convert Diagrams":
show_conversion_interface()
elif mode == "📝 Apply to Blog Posts":
show_application_interface()
def run_integrated_scan():
"""Run image scanning with progress display."""
with st.spinner("Scanning blog images..."):
progress_bar = st.progress(0)
status_text = st.empty()
# Initialize converters
converter = AnthropicMermaidConverter()
classifier = ImageClassifier(converter)
# Scan with progress updates
results = scan_with_progress(classifier, progress_bar, status_text)
# Save to session state
st.session_state.scan_results = results
st.success(f"✅ Scan complete! Found {results['total_diagrams']} diagrams out of {results['total_images']} images.")
st.rerun()
def save_conversions():
"""Persist conversions to cache file."""
cache_dir = Path('cache')
cache_dir.mkdir(exist_ok=True)
with open(cache_dir / 'conversions.json', 'w') as f:
json.dump(st.session_state.conversions, f, indent=2)
Results
The conversion was remarkably successful:
- 24 diagrams converted across 20 blog posts
- 100% success rate with high-quality Mermaid output
- Zero manual intervention required for conversions
Before and After
Here's an example from the WebSocket server post:
Before (Image):
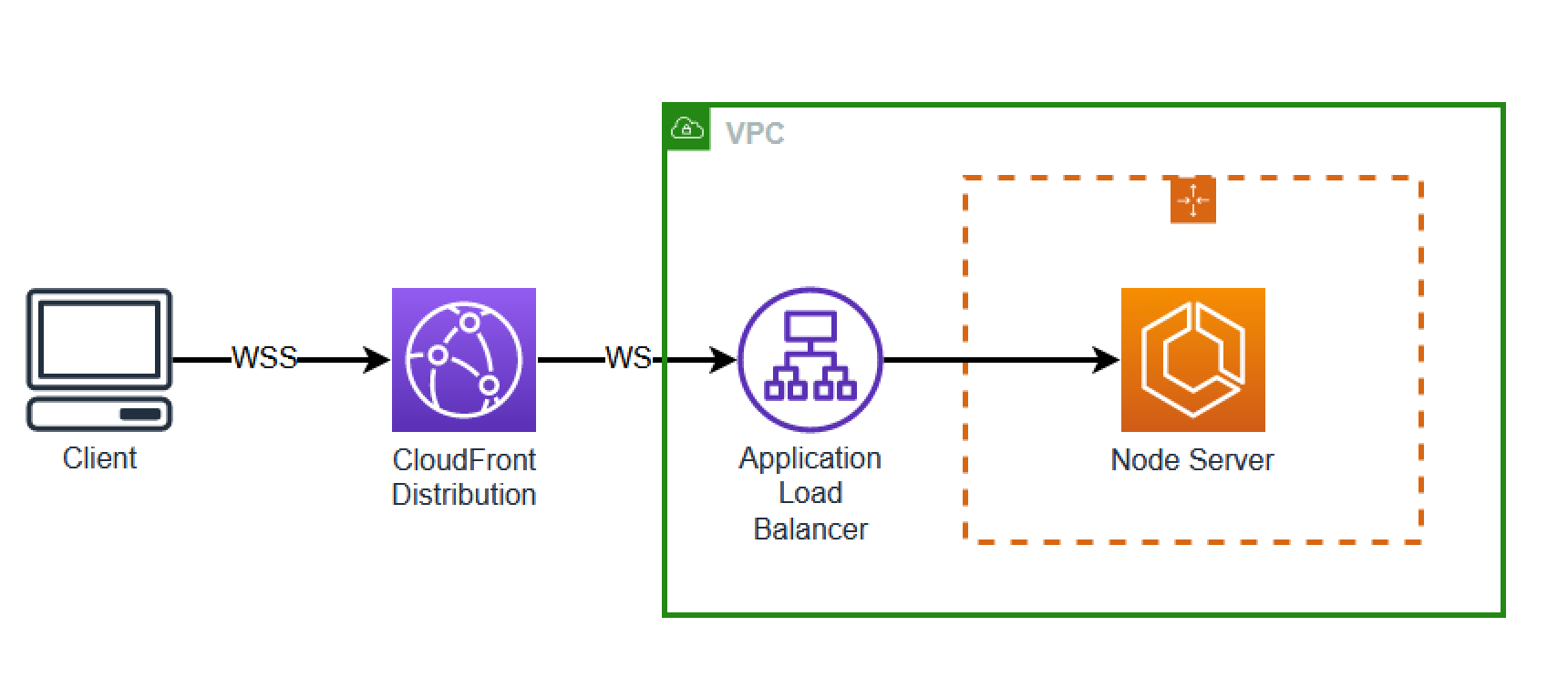
After (Mermaid):
flowchart LR
Client((Client))
CF[CloudFront<br/>Distribution]
subgraph VPC
ALB[Application<br/>Load Balancer]
subgraph ASG[Auto Scaling Group]
Node[Node Server]
end
end
Client -->|WSS| CF
CF -->|WS| ALB
ALB --> Node
style CF fill:#8C4FFF,color:#fff
style ALB fill:#8C4FFF,color:#fff
style Node fill:#FF9900,color:#fff
style VPC fill:#E9F3E6,stroke:#248814,stroke-width:2px
style ASG fill:#FFE5CC,stroke:#FF9900,stroke-width:2px,stroke-dasharray: 5 5
Benefits Realized
-
AI Assistants can now "see" diagrams: When readers ask Claude or other AI assistants about the architecture, they get accurate, context-aware responses
-
Better version control: Changes to diagrams now show meaningful diffs:
- Search[Search Lambda] + Search[Search Lambda with Cache] -
Easier maintenance: Updating a diagram is as simple as editing text
-
Improved accessibility: Screen readers can now convey diagram structure
-
Consistent styling: All diagrams follow the same visual language
Conclusion
Converting blog diagrams to Mermaid format significantly improved the AI-readability of my technical content. What started as a simple idea - making diagrams text-based - evolved into a powerful tool that automated the entire conversion process.
The result is a blog that's not just human-readable, but AI-readable too. When readers use AI assistants to understand the architectures I've written about, those assistants now have full context about system designs and relationships. In an age where AI coding assistants are becoming integral to development workflows, making our technical content AI-accessible is increasingly important.
The journey from 24 PNG files to Mermaid diagrams took just a few hours of development and a few minutes of processing - a small investment for a significant improvement in content accessibility.