
GitHub Repository Metrics: A Serverless AWS Implementation
Overview
This project implements a serverless solution for automatically collecting and analyzing GitHub repository metrics. It uses AWS services including Lambda, S3, Athena, Glue, and EventBridge to gather data from GitHub, store it efficiently, and make it available for analysis.
flowchart LR
GitHub((GitHub))
EventBridge[Amazon<br/>EventBridge]
Lambda[AWS Lambda<br/>Function]
S3[(S3 Bucket)]
Athena[Amazon<br/>Athena]
Glue[AWS Glue<br/>Database]
GitHub --> Lambda
EventBridge --> Lambda
Lambda <--> S3
Athena --> Glue
S3 <-- Query --> Glue
style EventBridge fill:#FF4F8B,color:#fff
style Lambda fill:#FF9900,color:#fff
style S3 fill:#569A31,color:#fff
style Athena fill:#8C4FFF,color:#fff
style Glue fill:#8C4FFF,color:#fff
GitHub
All code is available here: https://github.com/schuettc/github-insights
System Architecture
The solution consists of five main components:
- Lambda Function: Fetches data from GitHub API
- S3 Bucket: Stores data in Parquet format
- Glue Database and Table: Defines schema for the data
- Athena Workgroup and Query: Enables SQL-based analysis
- EventBridge Rule: Schedules daily data collection
Implementation Details
1. Lambda Function (LambdaResources)
The Lambda function is responsible for querying the GitHub API and writing the results to S3. It's implemented using Node.js and the AWS SDK.
export class LambdaResources extends Construct {
public insightQueryLambda: Function;
constructor(scope: Construct, id: string, props: LambdaResourcesProps) {
super(scope, id);
// ... role creation code omitted for brevity
this.insightQueryLambda = new NodejsFunction(this, "InsightsQueryLambda", {
entry: "./src/resources/insightQuery/index.ts",
runtime: Runtime.NODEJS_LATEST,
architecture: Architecture.ARM_64,
memorySize: 1024,
handler: "handler",
timeout: Duration.minutes(5),
role: insightQueryLambdaRole,
environment: {
LOG_LEVEL: props.logLevel,
GITHUB_TOKEN_SECRET_NAME: props.githubTokenSecretName,
INSIGHTS_BUCKET: props.insightsBucket.bucketName,
},
});
props.insightsBucket.grantReadWrite(this.insightQueryLambda);
}
}
Lambda Function Implementation
The core of the data collection is performed by the Lambda function. Here's a simplified version of the main handler:
export const handler = async (): Promise<void> => {
try {
const githubToken = await getGitHubToken();
const octokit = new Octokit({ auth: githubToken });
const repositories = await getRepositoriesFromS3();
const insights = await fetchRepositoryInsights(octokit, repositories);
await uploadInsightsToS3(insights);
} catch (error) {
console.error("Error in Lambda execution:", error);
throw error;
}
};
The fetchRepositoryInsights function is where the actual GitHub API calls occur:
async function fetchRepositoryInsights(
octokit: Octokit,
repositories: Repository[],
): Promise<RepoInsights[]> {
return (
await Promise.all(
repositories.map(async ({ owner, repo }) => {
try {
const repoData = await octokit.rest.repos.get({ owner, repo });
const [
issuesData,
pullRequestsData,
contributorsData,
releasesData,
commitsData,
] = await Promise.all([
octokit.rest.issues.listForRepo({ owner, repo, state: "all" }),
octokit.rest.pulls.list({ owner, repo, state: "all" }),
octokit.rest.repos.listContributors({ owner, repo }),
octokit.rest.repos
.getLatestRelease({ owner, repo })
.catch(() => null),
octokit.rest.repos.getCommitActivityStats({ owner, repo }),
]);
// Process and aggregate data
// ...
return {
repoName: `${owner}/${repo}`,
description: repoData.data.description || "",
stars: repoData.data.stargazers_count,
forks: repoData.data.forks_count,
openIssues: repoData.data.open_issues_count,
// ... other fields
};
} catch (error) {
console.error(`Error fetching data for ${owner}/${repo}:`, error);
return null;
}
}),
)
).filter((insight): insight is RepoInsights => insight !== null);
}
The collected data is then written to S3 in Parquet format:
async function uploadInsightsToS3(insights: RepoInsights[]): Promise<void> {
const schema = new parquet.ParquetSchema({
repoName: { type: "UTF8" },
description: { type: "UTF8" },
stars: { type: "INT64" },
// ... other fields
});
const writer = await ParquetWriter.openFile(schema, "/tmp/insights.parquet");
for (const insight of insights) {
await writer.appendRow({
...insight,
date: `${year}-${month}-${day}`,
});
}
await writer.close();
const fileContent = await fs.promises.readFile("/tmp/insights.parquet");
await s3Client.send(
new PutObjectCommand({
Bucket: process.env.INSIGHTS_BUCKET,
Key: `github-insights/year=${year}/month=${month}/day=${day}/insights_${timestamp}.parquet`,
Body: fileContent,
ContentType: "application/octet-stream",
}),
);
}
2. S3 Bucket (S3Resources)
The S3 bucket is used to store the GitHub repository to query and then to store the GitHub data in Parquet format. The data is partitioned by year, month, and day for efficient querying.
3. Glue Database and Table (GlueResources)
AWS Glue is used to define the schema for the GitHub data and set up partition projection.
export class GlueResources extends Construct {
public insightsDatabase: glue.CfnDatabase;
public insightsTable: CfnTable;
constructor(scope: Construct, id: string, props: GlueResourcesProps) {
super(scope, id);
// ... database creation code omitted for brevity
this.insightsTable = new glue.CfnTable(this, "GitHubInsightsTable", {
catalogId: Stack.of(this).account,
databaseName: this.insightsDatabase.ref,
tableInput: {
name: "github_insights",
tableType: "EXTERNAL_TABLE",
parameters: {
EXTERNAL: "TRUE",
"parquet.compression": "SNAPPY",
"projection.enabled": "true",
"projection.year.type": "integer",
"projection.year.range": "2020,2030",
"projection.year.digits": "4",
"projection.month.type": "integer",
"projection.month.range": "1,12",
"projection.month.digits": "2",
"projection.day.type": "integer",
"projection.day.range": "1,31",
"projection.day.digits": "2",
"storage.location.template": `s3://${props.insightsBucket.bucketName}/github-insights/year=$\{year}/month=$\{month}/day=$\{day}`,
},
storageDescriptor: {
// ... storage descriptor details omitted for brevity
},
partitionKeys: partitionKeys,
},
});
}
}
4. Athena Workgroup and Query (AthenaResources)
Amazon Athena is configured with a dedicated workgroup and a sample query for analyzing the GitHub data.
export class AthenaResources extends Construct {
constructor(scope: Construct, id: string, props: AthenaResourceProps) {
super(scope, id);
// ... workgroup creation code omitted for brevity
new athena.CfnNamedQuery(this, "GitHubInsightsSampleQuery", {
database: props.insightsDatabase.ref,
queryString: `
SELECT
reponame,
AVG(stars) as avg_stars,
AVG(forks) as avg_forks,
AVG(openissues) as avg_open_issues,
AVG(commitslastmonth) as avg_commits_last_month
FROM
github_insights
WHERE
year = '${new Date().getUTCFullYear()}'
AND month = '${(new Date().getUTCMonth() + 1)
.toString()
.padStart(2, "0")}'
GROUP BY
reponame
ORDER BY
avg_stars DESC
`,
description:
"Average stars, forks, open issues, and commits for each repository this month",
name: "GitHubInsightsMonthlyAverage",
workGroup: workgroup.ref,
});
}
}
5. EventBridge Rule (EventBridgeResources)
An EventBridge rule is set up to trigger the Lambda function daily.
export class EventBridgeResources extends Construct {
constructor(scope: Construct, id: string, props: EventBridgeResourcesProps) {
super(scope, id);
new Rule(this, "DailyLambdaTrigger", {
schedule: Schedule.cron({ minute: "0", hour: "0" }),
targets: [new LambdaFunction(props.insightQueryLambda)],
});
}
}
Data Flow
- The EventBridge rule triggers the Lambda function daily.
- The Lambda function fetches data from GitHub and writes it to S3 in Parquet format.
- The data is automatically partitioned in S3 based on the Glue table definition.
- Users can query the data using Athena, with the sample query providing a starting point for analysis.
Deployment
The entire infrastructure is defined using AWS CDK, allowing for version-controlled, reproducible deployments. The main stack is defined in the GitHubInsights class:
export class GitHubInsights extends Stack {
constructor(scope: Construct, id: string, props: GitHubInsightsProps) {
super(scope, id, props);
const s3Resources = new S3Resources(this, "S3Resources");
const glueResources = new GlueResources(this, "GlueResources", {
insightsBucket: s3Resources.insightsBucket,
});
new AthenaResources(this, "AthenaResources", {
insightsBucket: s3Resources.insightsBucket,
insightsDatabase: glueResources.insightsDatabase,
});
const lambdaResources = new LambdaResources(this, "LambdaResources", {
logLevel: props.logLevel,
insightsBucket: s3Resources.insightsBucket,
githubTokenSecretName: props.githubTokenSecretName,
});
new EventBridgeResources(this, "EventBridgeResources", {
insightQueryLambda: lambdaResources.insightQueryLambda,
});
}
}
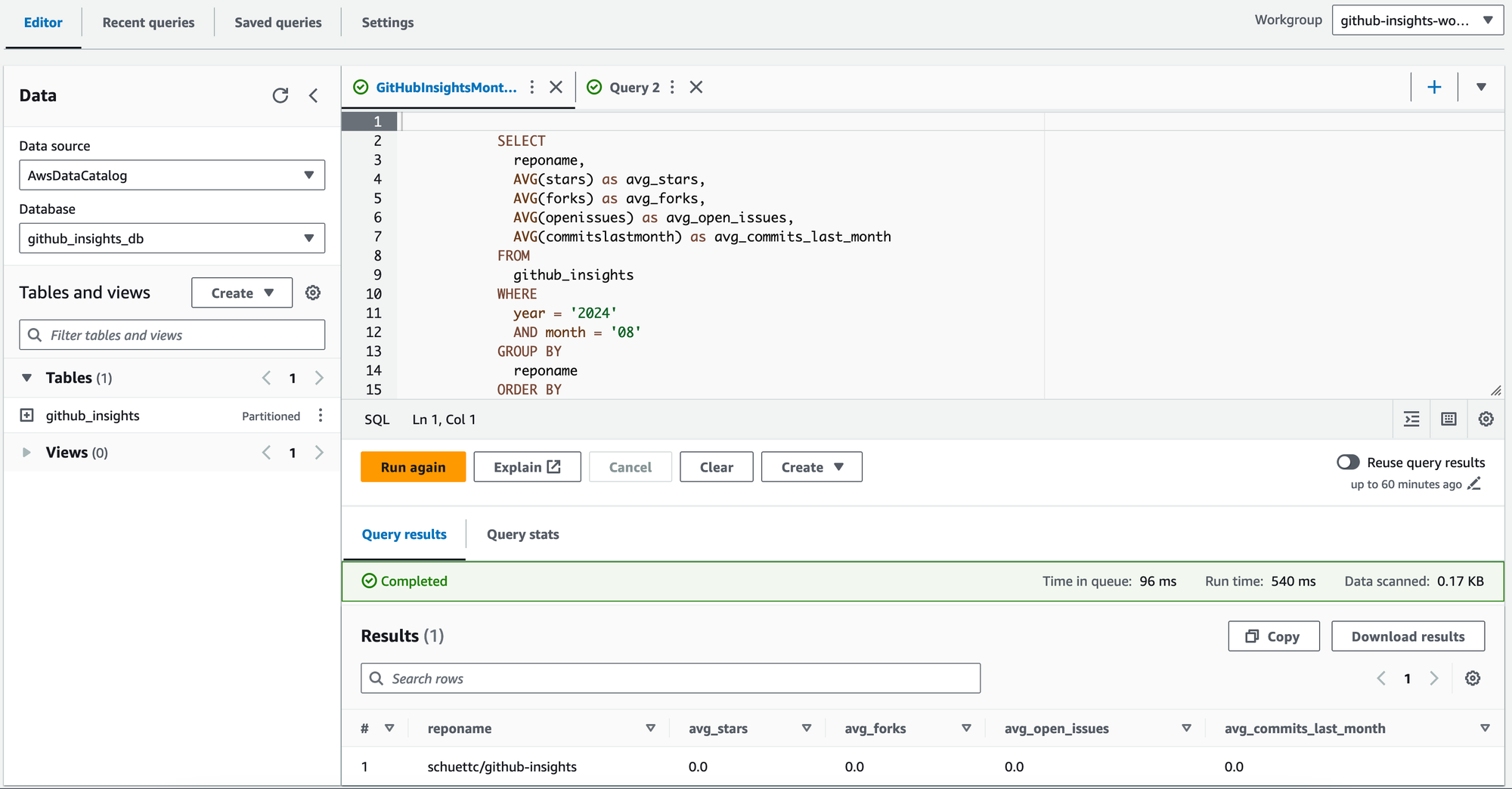
Querying Data with Athena
Once the data is stored in S3 and the Glue table is set up, users can query the data using Amazon Athena. Here are some example queries:
- Monthly average metrics for each repository:
SELECT
reponame,
AVG(stars) as avg_stars,
AVG(forks) as avg_forks,
AVG(openissues) as avg_open_issues,
AVG(commitslastmonth) as avg_commits_last_month
FROM
github_insights
WHERE
year = '2024'
AND month = '08'
GROUP BY
reponame
ORDER BY
avg_stars DESC
- Repositories with the most growth in stars over the last 30 days:
WITH current_stats AS (
SELECT reponame, stars
FROM github_insights
WHERE year = '2024' AND month = '08' AND day = '15'
),
previous_stats AS (
SELECT reponame, stars
FROM github_insights
WHERE year = '2024' AND month = '07' AND day = '16'
)
SELECT
c.reponame,
c.stars - p.stars AS star_growth,
((c.stars - p.stars) / p.stars) * 100 AS growth_percentage
FROM current_stats c
JOIN previous_stats p ON c.reponame = p.reponame
ORDER BY star_growth DESC
LIMIT 10
- Repositories with the highest ratio of closed to open issues:
SELECT
reponame,
AVG(closedissues) as avg_closed_issues,
AVG(openissues) as avg_open_issues,
AVG(closedissues) / NULLIF(AVG(openissues), 0) as closed_to_open_ratio
FROM
github_insights
WHERE
year = '2024'
AND month = '08'
GROUP BY
reponame
HAVING
AVG(openissues) > 0
ORDER BY
closed_to_open_ratio DESC
LIMIT 10
To run these queries:
- Open the Athena console in AWS.
- Select the
github_insights_dbdatabase. - Enter the SQL query in the query editor.
- Click "Run query" to execute and view the results.
The partition projection set up in the Glue table definition allows Athena to efficiently query the data without the need for manual partition management, making it easy to analyze historical trends and current repository states.
Deploying
Configuration Files
1. .env
This file contains environment variables used by the scripts and the CDK deployment.
Example content:
GITHUB_TOKEN_SECRET=gph_xxxxxxxxxxx
STACK_NAME=GitHubInsights
AWS_REGION=us-east-1
Fields:
GITHUB_TOKEN_SECRET: Your GitHub personal access token. You will need to create one within GitHub.STACK_NAME: The name of your CDK stack (used byupload_repo_list.sh).AWS_REGION: The AWS region where your resources are deployed.
Note: Never commit the .env file to version control. It's included in .gitignore by default.
2. repositories.json
This file contains the list of GitHub repositories you want to monitor.
Example content:
[
{
"owner": "schuettc",
"repo": "github-insights"
}
]
Usage:
- Add or remove repository objects as needed.
- Each repository object should have an "owner" and "repo" field.
- After modifying this file, run
upload_repo_list.shto update the list in your S3 bucket.
Helper Scripts
1. setup_github_token.sh
This script is used to securely store your GitHub token in AWS Secrets Manager.
Purpose:
- Creates or updates a secret in AWS Secrets Manager to store your GitHub token.
- Allows secure access to the GitHub API without exposing the token in your code.
Usage:
- Ensure you have the AWS CLI configured with appropriate permissions.
- Create a
.envfile in the project root (see Configuration Files section below). - Run the script:
./setup_github_token.sh
What it does:
- Reads the
GITHUB_TOKEN_SECRETfrom the.envfile. - Creates or updates a secret in AWS Secrets Manager with the provided token.
- Uses the
GITHUB_TOKEN_SECRET_NAME(default: "/github_insights/github_token") as the secret name. - Sets the AWS region based on the
AWS_REGIONin.envor defaults to "us-east-1".
2. upload_repo_list.sh
This script uploads the list of repositories to be monitored to your S3 bucket.
Purpose:
- Uploads the
repositories.jsonfile to the S3 bucket created by the CDK stack. - Allows you to easily update the list of repositories to be monitored.
Usage:
- Ensure you have the AWS CLI configured with appropriate permissions.
- Update the
repositories.jsonfile with the repositories you want to monitor. - Run the script:
./upload_repo_list.sh
What it does:
- Retrieves the S3 bucket name from the CloudFormation stack outputs.
- Uploads the
repositories.jsonfile to the root of the S3 bucket. - Uses the
STACK_NAMEfrom the.envfile to identify the correct CloudFormation stack. - Sets the AWS region based on the
AWS_REGIONin.envor defaults to "us-east-1".
Workflow
- Set up your
.envfile with your GitHub token and stack name. - Deploy your CDK stack by running
yarn launch - Run
setup_github_token.shto securely store your GitHub token. - Update
repositories.jsonwith the list of repositories you want to monitor. - Run
upload_repo_list.shto upload the repository list to your S3 bucket.
By following this workflow, you ensure that your GitHub token is securely stored and your Lambda function has the latest list of repositories to monitor.
Conclusion
This serverless architecture provides an efficient method for collecting and analyzing GitHub repository metrics. It leverages AWS services to automate data collection, storage, and query capabilities, enabling data-driven insights into repository activity and health.